DEPRECATION NOTICE: The on-ramp codelabs are currently in the process of being deprecated in favor of content in the user manual. If anything seems out of date in this content, please refer to the user manual content on the Slurm workload manager.
Because CRC operates a shared resource for the Pitt research community, there needs to be a tool that ensure fair and equitable access.
CRC uses the SLURM workload manager to accomplish this. This is a batch queueing system that will allocate resources based on defined policies.
Users submit "jobs" to SLURM via scripts that outline the resources to be requested.
Upon submission to SLURM, the jobs are queued within a scheduling system. They run when the requested resources become available, so long as the request is in accordance with scheduling policies.
Shown below is the architecture of a SLURM job submission script
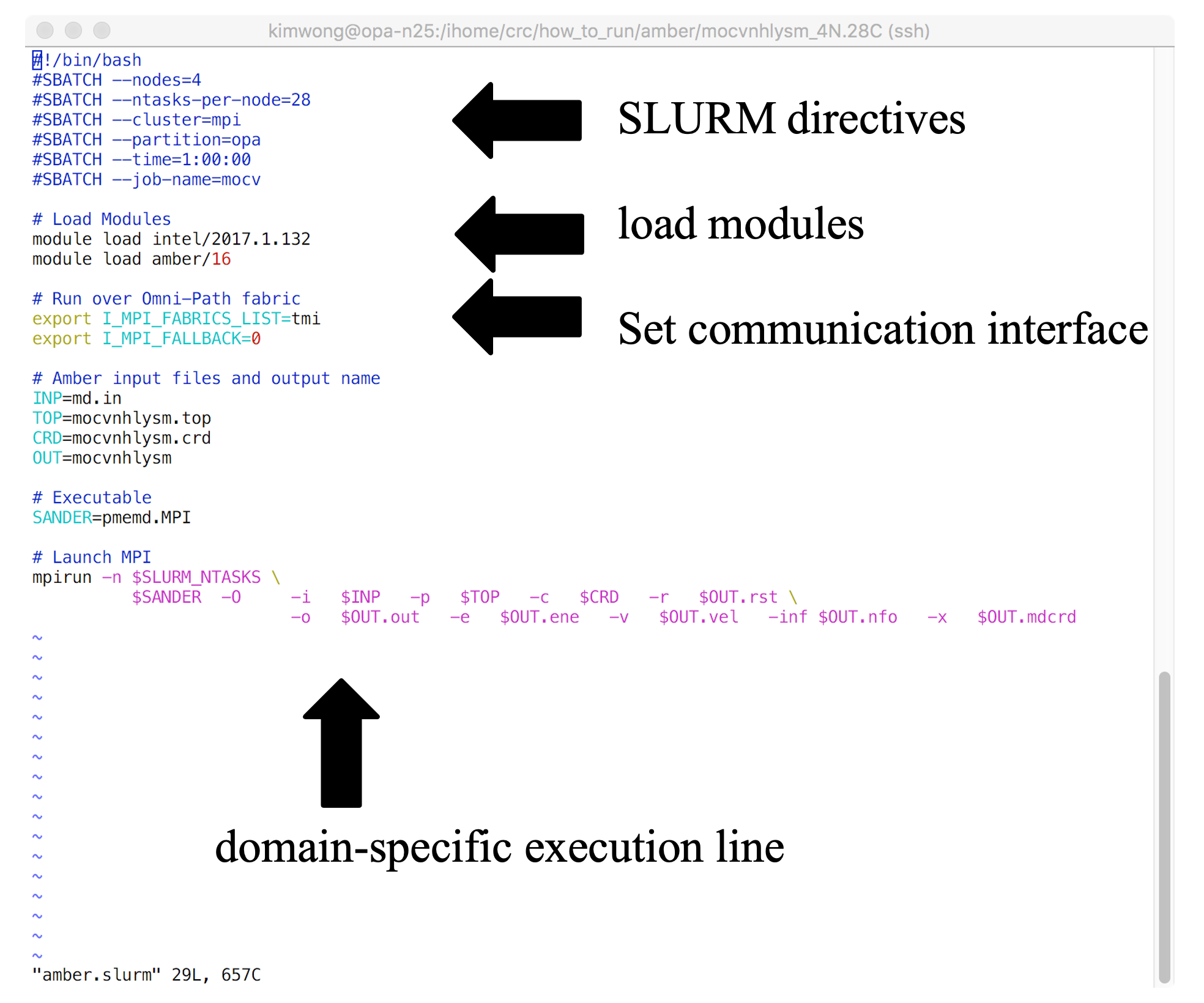
The SLURM job submission script is essentially a text file that contains (1) commands to SLURM, (2) commands to Lmod, (3) any environment settings for communication or software, and (4) the application-specific execution command. The commands execute sequentially line-by-line from top to bottom (unless you background the command with an & at the end). CRC provides a growing number of example job submission scripts for specific software applications
[username@login1 ~]$ ls /ihome/crc/how_to_run/ abaqus ansys comsol DeepLabCut-1.02 febio gaussian hello-world julia lumerical matlab mopac nektar++ pbdr quantumespresso stata vasp abm bioeng2370_2021f cp2k deformetrica fluent gpaw hfss lammps lumerical.test molecularGSM mosek openfoam psi4 r tinker westpa amber blender damask fdtd gamess gromacs ipc lightgbm lumerical.test2 molpro namd orca qchem sas turbomole xilinx
Example Submission Script
[username@login1 ~]$ cd [username@login1 ~]$ pwd /ihome/groupname/username [username@login1 ~]$ cp -rp /ihome/crc/how_to_run/amber/mocvnhlysm_1N.24C_OMPI_SMP . [username@login1 ~]$ cp -rp /ihome/crc/how_to_run/amber/mocvnhlysm_1titanX.1C . [username@login1 ~]$ cp -rp /ihome/crc/how_to_run/amber/mocvnhlysm_2GTX1080.2C . [username@login1 ~]$ ls CRC Desktop mocvnhlysm_1N.24C_OMPI_SMP mocvnhlysm_1titanX.1C mocvnhlysm_2GTX1080.2C zzz_cleanmeup
First let's go into the mocvnhlysm_1N.24C_OMPI_SMP directory and show the contents of the SLURM submission script
[username@login1 ~]$ cd mocvnhlysm_1N.24C_OMPI_SMP [username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$ ls amber.slurm logfile md.in mocvnhlysm.crd mocvnhlysm.nfo mocvnhlysm.rst mocvnhlysm.top [username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$ cat amber.slurm
#!/bin/bash
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=12
#SBATCH --cluster=smp
#SBATCH --partition=high-mem
#SBATCH --time=1:00:00
#SBATCH --job-name=mocv
# Load Modules
module purge
module load gcc/5.4.0
module load openmpi/3.0.0
module load amber/16_gcc-5.4.0
# Run over Omni-Path fabric
#export I_MPI_FABRICS_LIST=tmi
#export I_MPI_FALLBACK=0
# Amber input files and output name
INP=md.in
TOP=mocvnhlysm.top
CRD=mocvnhlysm.crd
OUT=mocvnhlysm
# Executable
SANDER=pmemd.MPI
# Launch MPI
mpirun -n $SLURM_NTASKS \
$SANDER -O -i $INP -p $TOP -c $CRD -r $OUT.rst \
-o $OUT.out -e $OUT.ene -v $OUT.vel -inf $OUT.nfo -x $OUT.mdcrd
The SLURM directives begin with the #SBATCH prefix and instructs the scheduler to allocate 1 node with 12 cores within the high-mem partition on the smp cluster for 1 hour. Then the submission script loads the Amber molecular dynamics package and dependencies, followed by application-specific execution syntax.
A Note on Multiple SLURM Allocation Associations
Submitting a Job
Use sbatch to submit the job:
[username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$ sbatch amber.slurm
Submitted batch job 5103575 on cluster smp
[username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$ squeue -M smp -u $USER
CLUSTER: smp
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
5103575 high-mem mocv username R 0:18 1 smp-512-n1
[username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$ tail mocvnhlysm.out |--------------------------------------------------- NSTEP = 500 TIME(PS) = 2021.000 TEMP(K) = 300.08 PRESS = 0.0 Etot = -292450.7926 EKtot = 68100.1600 EPtot = -360550.9527 BOND = 534.0932 ANGLE = 1306.5392 DIHED = 1661.1194 1-4 NB = 555.1360 1-4 EEL = 4509.5203 VDWAALS = 51060.9002 EELEC = -420178.2610 EHBOND = 0.0000 RESTRAINT = 0.0000 Ewald error estimate: 0.1946E-03 ------------------------------------------------------------------------------ [username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$
Every job submission is assigned a "Job ID". In this case it is 5103575.
Use the squeue command to check on the status of submitted jobs. The -M option is to specify the cluster and the -u flag is used to only output information for a particular username.
[username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$ echo $USER
username
[username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$ squeue -M smp -u $USER
CLUSTER: smp
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
[username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$ tail -30 mocvnhlysm.out
| Total 14.01 5.51
| PME Load Balancing CPU Time, Average for All Tasks:
|
| Routine Sec %
| ------------------------------------
| Atom Reassign 0.01 0.00
| Image Reassign 0.01 0.00
| FFT Reassign 0.01 0.00
| ------------------------------------
| Total 0.02 0.01
| Final Performance Info:
| -----------------------------------------------------
| Average timings for last 0 steps:
| Elapsed(s) = 0.07 Per Step(ms) = Infinity
| ns/day = 0.00 seconds/ns = Infinity
|
| Average timings for all steps:
| Elapsed(s) = 254.36 Per Step(ms) = 50.87
| ns/day = 3.40 seconds/ns = 25436.13
| -----------------------------------------------------
| Master Setup CPU time: 0.54 seconds
| Master NonSetup CPU time: 254.10 seconds
| Master Total CPU time: 254.64 seconds 0.07 hours
| Master Setup wall time: 3 seconds
| Master NonSetup wall time: 254 seconds
| Master Total wall time: 257 seconds 0.07 hours
[username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$
In the time needed to write the descriptions, the job had completed.
If you leave out the -u option to squeue, you get reporting of everyone's jobs on the specified cluster:
[username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$ squeue -M smp
CLUSTER: smp
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
5046724 smp desf_y_1 sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
5046730 smp isof_y_1 sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
5046732 smp enfl_y_1 sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
5046760 smp enfl_pf_ sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
5046761 smp enfl_pcl sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
5046762 smp isof_pcl sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
5046763 smp isof_poc sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
5046773 smp desf_pf_ sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
5046780 smp desf_poc sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
5046853 smp desf_bo_ sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
5046869 smp isof_bo_ sadowsky PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4304639 smp run_mrs. taa80 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158825 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158826 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158827 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158828 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158829 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158830 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158831 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158832 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158833 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158834 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158835 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158836 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158837 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158838 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158839 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158840 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158841 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158842 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158843 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
3158844 smp methane/ sum57 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4684270 smp reverse has197 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4684271 smp generate has197 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4120436 high-mem chr7 kowaae22 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4120437 high-mem chr6 kowaae22 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4120438 high-mem chr5 kowaae22 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4120439 high-mem chr4 kowaae22 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4120440 high-mem chr3 kowaae22 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4120441 high-mem chr2 kowaae22 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4120443 high-mem chr1 kowaae22 PD 0:00 1 (AssocGrpCPURunMinutesLimit)
4684277 smp reverse has197 PD 0:00 1 (Dependency)
4684278 smp generate has197 PD 0:00 1 (Dependency)
5097014 high-mem eom jmb503 PD 0:00 1 (MaxCpuPerAccount)
4917460_468 smp canP13 ryanp PD 0:00 1 (launch failed requeued held)
5085232 high-mem T2T_CENP mam835 R 2-11:54:39 1 smp-256-n2
5085230 high-mem T2T_CENP mam835 R 2-11:54:49 1 smp-256-n1
5091263 smp bowtie_c sat143 R 9:48:55 1 smp-n192
5080187 high-mem LCuH_dim yuz171 R 1-16:03:36 1 smp-3072-n1
5086871 smp 24-1_17- jsh89 R 1-13:40:04 1 smp-n86
5095388 smp sampled_ sem156 R 1:04:09 1 smp-n20
5095387 smp sampled_ sem156 R 1:23:19 1 smp-n21
5095386 smp sampled_ sem156 R 1:47:10 1 smp-n16
5095385 smp sampled_ sem156 R 2:20:17 1 smp-n5
5095384 smp sampled_ sem156 R 2:23:30 1 smp-n11
5095382 smp sampled_ sem156 R 2:31:08 1 smp-n6
5095378 smp sampled_ sem156 R 3:14:25 1 smp-n3
5089347_250 smp RFshim ans372 R 2:30:41 1 smp-n195
5089347_249 smp RFshim ans372 R 2:31:14 1 smp-n98
5089347_248 smp RFshim ans372 R 2:32:59 1 smp-n152
5089347_247 smp RFshim ans372 R 2:34:46 1 smp-n111
5089347_246 smp RFshim ans372 R 2:35:51 1 smp-n51
GPU Cluster Example 1
Now let's take a look at a job submission script to the gpu cluster
[username@login1 ~]$ cd [username@login1 ~]$ cd mocvnhlysm_1titanX.1C [username@login1 mocvnhlysm_1titanX.1C]$ pwd /ihome/groupname/username/mocvnhlysm_1titanX.1C [username@login1 mocvnhlysm_1titanX.1C]$ ls amber.slurm md.in mocvnhlysm.crd mocvnhlysm.nfo mocvnhlysm.rst mocvnhlysm.top [username@login1 mocvnhlysm_1titanX.1C]$ cat amber.slurm
#!/bin/bash
#SBATCH --job-name=gpus-1
#SBATCH --output=gpus-1.out
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --cluster=gpu
#SBATCH --partition=titanx
#SBATCH --gres=gpu:1
#SBATCH --time=24:00:00
# Load Modules
module purge
module load cuda/7.5.18
module load amber/16-titanx
# Amber input files and output name
INP=md.in
TOP=mocvnhlysm.top
CRD=mocvnhlysm.crd
OUT=mocvnhlysm
# Executable
SANDER=pmemd.cuda
# Launch PMEMD.CUDA
echo AMBERHOME $AMBERHOME
echo SLURM_NTASKS $SLURM_NTASKS
nvidia-smi
$SANDER -O -i $INP -p $TOP -c $CRD -r $OUT.rst \
-o $OUT.out -e $OUT.ene -v $OUT.vel -inf $OUT.nfo -x $OUT.mdcrd
The content of this job submission script is similar to the one for the smp cluster, with key differences in the SLURM directives and the specification of the GPU-accelerated Amber package and executable.
Here, we are requesting
1node1Core1GPU- on the
titanxpartition - in the
gpucluster
- on the
24hours wall-time
We submit the job using the sbatch command.
[username@login1 mocvnhlysm_1titanX.1C]$ sbatch amber.slurm
Submitted batch job 260052 on cluster gpu
[username@login1 mocvnhlysm_1titanX.1C]$ squeue -M gpu -u $USER
CLUSTER: gpu
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
260052 titanx gpus-1 username R 0:06 1 gpu-stage06
[username@login1 mocvnhlysm_1titanX.1C]$ tail mocvnhlysm.out
------------------------------------------------------------------------------
NSTEP = 1000 TIME(PS) = 2022.000 TEMP(K) = 301.12 PRESS = 0.0
Etot = -292271.3092 EKtot = 68336.6875 EPtot = -360607.9967
BOND = 490.8433 ANGLE = 1305.8711 DIHED = 1690.9079
1-4 NB = 555.5940 1-4 EEL = 4530.8677 VDWAALS = 51423.4399
EELEC = -420605.5206 EHBOND = 0.0000 RESTRAINT = 0.0000
------------------------------------------------------------------------------
[username@login1 mocvnhlysm_1titanX.1C]$
While this job is running, let's run the other GPU-accelerated example:
[username@login1 mocvnhlysm_1titanX.1C]$ cd ../mocvnhlysm_2GTX1080.2C/ [username@login1 mocvnhlysm_2GTX1080.2C]$ cat amber.slurm
#!/bin/bash
#SBATCH --job-name=gpus-2
#SBATCH --output=gpus-2.out
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=2
#SBATCH --cluster=gpu
#SBATCH --partition=gtx1080
#SBATCH --gres=gpu:2
#SBATCH --time=24:00:00
# Load Modules
module purge
module load cuda/8.0.44
module load amber/16-gtx1080
# Amber input files and output name
INP=md.in
TOP=mocvnhlysm.top
CRD=mocvnhlysm.crd
OUT=mocvnhlysm
# Executable
SANDER=pmemd.cuda.MPI
# Launch PMEMD.CUDA
echo AMBERHOME $AMBERHOME
echo SLURM_NTASKS $SLURM_NTASKS
nvidia-smi
mpirun -n $SLURM_NTASKS \
$SANDER -O -i $INP -p $TOP -c $CRD -r $OUT.rst \
-o $OUT.out -e $OUT.ene -v $OUT.vel -inf $OUT.nfo -x $OUT.mdcrd
In this example, we are requesting:
1Node2Cores2GPUs- on the
gtx1080partition - of the
gpucluster
- on the
Submit the job using sbatch and check on the queue
[username@login1 mocvnhlysm_2GTX1080.2C]$ squeue -M gpu -u $USER
CLUSTER: gpu
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
260052 titanx gpus-1 username R 6:15 1 gpu-stage06
[username@login1 mocvnhlysm_2GTX1080.2C]$ sbatch amber.slurm
Submitted batch job 260053 on cluster gpu
[username@login1 mocvnhlysm_2GTX1080.2C]$ squeue -M gpu -u $USER
CLUSTER: gpu
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
260053 gtx1080 gpus-2 username R 0:04 1 gpu-n25
260052 titanx gpus-1 username R 6:23 1 gpu-stage06
[username@login1 mocvnhlysm_2GTX1080.2C]$
You see that we now have two jobs running on the GPU cluster, one on the titanx partition and the other on the gtx1080 partition.
You might wonder,
is there any way I can see the state of the cluster and the partitions?
You can use the sinfo command to list the current state.
[username@login1 mocvnhlysm_2GTX1080.2C]$ sinfo -M gpu CLUSTER: gpu PARTITION AVAIL TIMELIMIT NODES STATE NODELIST gtx1080* up infinite 1 drain gpu-stage08 gtx1080* up infinite 13 mix gpu-n[16-19,22-25],gpu-stage[09-11,13-14] gtx1080* up infinite 3 idle gpu-n[20-21],gpu-stage12 titanx up infinite 4 mix gpu-stage[02,04-06] titanx up infinite 3 idle gpu-stage[01,03,07] k40 up infinite 1 idle smpgpu-n0 v100 up infinite 1 mix gpu-n27 power9 up infinite 4 idle ppc-n[1-4] scavenger up infinite 1 drain gpu-stage08 scavenger up infinite 18 mix gpu-n[16-19,22-25,27],gpu-stage[02,04-06,09-11,13-14] scavenger up infinite 7 idle gpu-n[20-21],gpu-stage[01,03,07,12],smpgpu-n0 a100 up infinite 1 mix gpu-n28 a100 up infinite 2 idle gpu-n[29-30]
To see all the cluster info, pass a comma separate list of cluster names to the -M flag
[username@login1 mocvnhlysm_2GTX1080.2C]$ sinfo -M smp,gpu,mpi,htc CLUSTER: gpu PARTITION AVAIL TIMELIMIT NODES STATE NODELIST gtx1080* up infinite 1 drain gpu-stage08 gtx1080* up infinite 13 mix gpu-n[16-19,22-25],gpu-stage[09-11,13-14] gtx1080* up infinite 3 idle gpu-n[20-21],gpu-stage12 titanx up infinite 4 mix gpu-stage[02,04-06] titanx up infinite 3 idle gpu-stage[01,03,07] k40 up infinite 1 idle smpgpu-n0 v100 up infinite 1 mix gpu-n27 power9 up infinite 4 idle ppc-n[1-4] scavenger up infinite 1 drain gpu-stage08 scavenger up infinite 18 mix gpu-n[16-19,22-25,27],gpu-stage[02,04-06,09-11,13-14] scavenger up infinite 7 idle gpu-n[20-21],gpu-stage[01,03,07,12],smpgpu-n0 a100 up infinite 1 mix gpu-n28 a100 up infinite 2 idle gpu-n[29-30] CLUSTER: htc PARTITION AVAIL TIMELIMIT NODES STATE NODELIST htc* up infinite 11 mix htc-n[28-29,100-103,107-110,112] htc* up infinite 2 alloc htc-n[27,105] htc* up infinite 29 idle htc-n[0-26,30-31] scavenger up infinite 11 mix htc-n[28-29,100-103,107-110,112] scavenger up infinite 2 alloc htc-n[27,105] scavenger up infinite 29 idle htc-n[0-26,30-31] CLUSTER: mpi PARTITION AVAIL TIMELIMIT NODES STATE NODELIST opa* up infinite 2 down* opa-n[63,77] opa* up infinite 81 alloc opa-n[0-45,50-53,55-56,61-62,64-76,78-83,88-95] opa* up infinite 12 idle opa-n[46-49,57-60,84-87] opa* up infinite 1 down opa-n54 opa-high-mem up infinite 36 alloc opa-n[96-131] ib up infinite 6 resv ib-n[0-3,12-13] ib up infinite 12 alloc ib-n[4-5,7-11,18-19,26-28] ib up infinite 14 idle ib-n[6,14-17,20-25,29-31] scavenger up infinite 2 down* opa-n[63,77] scavenger up infinite 117 alloc opa-n[0-45,50-53,55-56,61-62,64-76,78-83,88-131] scavenger up infinite 12 idle opa-n[46-49,57-60,84-87] scavenger up infinite 1 down opa-n54 CLUSTER: smp PARTITION AVAIL TIMELIMIT NODES STATE NODELIST smp* up infinite 3 down* smp-n[0,8,151] smp* up infinite 124 mix smp-n[1,24-32,34-37,39-40,42-44,47-49,51-53,55,57-58,60,62-63,65-66,68-69,73-75,77,80-82,84-92,96-98,101-103,105-107,109-111,113-114,116,119,126-127,131-132,134-138,140,143-144,150,152-153,157-165,167-168,171,173-181,183-184,187,189-200,202,204-205,207-208,210] smp* up infinite 49 alloc smp-n[2,4-6,11,13-14,16,20-21,23,33,38,41,50,54,56,59,61,64,67,70-71,78-79,99-100,104,108,112,115,121-122,129,133,139,142,145,154-156,166,169-170,182,185,188,201,206] smp* up infinite 30 idle smp-n[3,7,9-10,12,15,19,22,45-46,72,76,83,93-95,117-118,120,128,130,141,146-149,172,186,203,209] high-mem up infinite 6 mix smp-256-n[1-2],smp-3072-n[0-3] high-mem up infinite 1 alloc smp-nvme-n1 high-mem up infinite 3 idle smp-512-n[1-2],smp-1024-n0 legacy up infinite 2 mix legacy-n[13,16] legacy up infinite 5 alloc legacy-n[7-11] legacy up infinite 12 idle legacy-n[0-6,14-15,17-19] legacy up infinite 1 down legacy-n12 scavenger up infinite 3 down* smp-n[0,8,151] scavenger up infinite 132 mix legacy-n[13,16],smp-256-n[1-2],smp-3072-n[0-3],smp-n[1,24-32,34-37,39-40,42-44,47-49,51-53,55,57-58,60,62-63,65-66,68-69,73-75,77,80-82,84-92,96-98,101-103,105-107,109-111,113-114,116,119,126-127,131-132,134-138,140,143-144,150,152-153,157-165,167-168,171,173-181,183-184,187,189-200,202,204-205,207-208,210] scavenger up infinite 55 alloc legacy-n[7-11],smp-n[2,4-6,11,13-14,16,20-21,23,33,38,41,50,54,56,59,61,64,67,70-71,78-79,99-100,104,108,112,115,121-122,129,133,139,142,145,154-156,166,169-170,182,185,188,201,206],smp-nvme-n1 scavenger up infinite 45 idle legacy-n[0-6,14-15,17-19],smp-512-n[1-2],smp-1024-n0,smp-n[3,7,9-10,12,15,19,22,45-46,72,76,83,93-95,117-118,120,128,130,141,146-149,172,186,203,209] scavenger up infinite 1 down legacy-n12
You can use a similar syntax for the squeue command to see all the jobs you have submitted.
[username@login1 mocvnhlysm_2GTX1080.2C]$ squeue -M smp,gpu,mpi,htc -u $USER
CLUSTER: gpu
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
260052 titanx gpus-1 username R 14:46 1 gpu-stage06
CLUSTER: htc
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
CLUSTER: mpi
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
CLUSTER: smp
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
[username@login1 mocvnhlysm_2GTX1080.2C]$ sbatch amber.slurm
Submitted batch job 260055 on cluster gpu
[username@login1 mocvnhlysm_2GTX1080.2C]$ cd ../mocvnhlysm_1N.24C_OMPI_SMP/
[username@login1 mocvnhlysm_1N.24C_OMPI_SMP]$ sbatch amber.slurm
[username@login1 mocvnhlysm_2GTX1080.2C]$ squeue -M smp,gpu,mpi,htc -u $USER
CLUSTER: gpu
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
260055 gtx1080 gpus-2 username R 0:03 1 gpu-n25
260052 titanx gpus-1 username R 15:46 1 gpu-stage06
CLUSTER: htc
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
CLUSTER: mpi
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
CLUSTER: smp
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
5105649 high-mem mocv username R 0:28 1 smp-512-n1
Example 3: Changing the partition
Next, we will change the job submission script to submit to the v100 partition on the gpu cluster
[username@login1 ~]$ cp -rp mocvnhlysm_1titanX.1C mocvnhlysm_1v100.1C [username@login1 ~]$ cd mocvnhlysm_1v100.1C [username@login1 mocvnhlysm_1v100.1C]$ vi amber.slurm [username@login1 mocvnhlysm_1v100.1C]$ head amber.slurm
#!/bin/bash
#SBATCH --job-name=gpus-1
#SBATCH --output=gpus-1.out
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --cluster=gpu
#SBATCH --partition=v100
#SBATCH --gres=gpu:1
#SBATCH --time=24:00:00
[username@login1 mocvnhlysm_1v100.1C]$ sbatch amber.slurm
Submitted batch job 260056 on cluster gpu
[username@login1 mocvnhlysm_1v100.1C]$ squeue -M smp,gpu,mpi,htc -u $USER
CLUSTER: gpu
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
260056 v100 gpus-1 username PD 0:00 1 (Priority)
260052 titanx gpus-1 username R 20:44 1 gpu-stage06
CLUSTER: htc
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
CLUSTER: mpi
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
CLUSTER: smp
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
To obtain more information about why the job is in the Pending (PD) state, use the scontrol command:
[username@login1 mocvnhlysm_1v100.1C]$ scontrol -M gpu show job 260056 JobId=260056 JobName=gpus-1 UserId=username(152289) GroupId=groupname(16260) MCS_label=N/A Priority=2367 Nice=0 Account=sam QOS=gpu-v100-s JobState=PENDING Reason=Priority Dependency=(null) Requeue=1 Restarts=0 BatchFlag=1 Reboot=0 ExitCode=0:0 RunTime=00:00:00 TimeLimit=1-00:00:00 TimeMin=N/A SubmitTime=2022-01-26T08:20:43 EligibleTime=2022-01-26T08:20:43 AccrueTime=2022-01-26T08:20:43 StartTime=Unknown EndTime=Unknown Deadline=N/A SuspendTime=None SecsPreSuspend=0 LastSchedEval=2022-01-26T08:24:34 Partition=v100 AllocNode:Sid=login1:25474 ReqNodeList=(null) ExcNodeList=(null) NodeList=(null) NumNodes=1-1 NumCPUs=1 NumTasks=1 CPUs/Task=1 ReqB:S:C:T=0:0:*:* TRES=cpu=1,mem=5364M,node=1,billing=5,gres/gpu=1 Socks/Node=* NtasksPerN:B:S:C=1:0:*:* CoreSpec=* MinCPUsNode=1 MinMemoryCPU=5364M MinTmpDiskNode=0 Features=(null) DelayBoot=00:00:00 OverSubscribe=OK Contiguous=0 Licenses=(null) Network=(null) Command=/ihome/groupname/username/mocvnhlysm_1v100.1C/amber.slurm WorkDir=/ihome/groupname/username/mocvnhlysm_1v100.1C StdErr=/ihome/groupname/username/mocvnhlysm_1v100.1C/gpus-1.out StdIn=/dev/null StdOut=/ihome/groupname/username/mocvnhlysm_1v100.1C/gpus-1.out Power= TresPerNode=gpu:1 MailUser=(null) MailType=NONE
If you realize that you made a mistake in the inputs for your job submission script, you can cancel the job with the scancel command:
[username@login1 mocvnhlysm_1v100.1C]$ squeue -M smp,gpu,mpi,htc -u $USER
CLUSTER: gpu
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
260056 v100 gpus-1 username PD 0:00 1 (Priority)
260052 titanx gpus-1 username R 26:07 1 gpu-stage06
CLUSTER: htc
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
CLUSTER: mpi
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
CLUSTER: smp
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
[username@login1 mocvnhlysm_1v100.1C]$ scancel -M gpu 260056
[username@login1 mocvnhlysm_1v100.1C]$ squeue -M smp,gpu,mpi,htc -u $USER
CLUSTER: gpu
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
260052 titanx gpus-1 username R 26:24 1 gpu-stage06
CLUSTER: htc
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
CLUSTER: mpi
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
CLUSTER: smp
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
That's it! Once you become familiar with these handful of commands, you should become proficient in leveraging all the compute-resources for your research.
The hardest part is crafting the job submission script; however, CRC is building a collection of examples within the directory /ihome/crc/how_to_run/ that might address your specific application.
- Website Home: https://crc.pitt.edu
- Getting Started: https://crc.pitt.edu/getting-started/requesting-new-account
- User Manual: https://crc-pages.pitt.edu/user-manual/
The best way to get help on a specific issue is to submit a help ticket. You should log in to the CRC website using your Pitt credentials first.
Please return to the Pitt CRC Codelabs dashboard and find the "CRC Helper Scripts" codelab, or use this link